
MiroThinker-1.7 & H1: Towards Heavy-Duty Research Agents via Verification
Moving from LLM chatbots to accurate long-chain solvers for critical tasks
Moving from LLM chatbots to accurate long-chain solvers for critical tasks
Today, we release our latest research agent family: MiroThinker-1.7 and MiroThinker-H1. Built upon MiroThinker-1.7, MiroThinker-H1 further extends the system with heavy-duty reasoning capabilities. This marks our effort towards a new vision of AI: moving beyond LLM chatbots towards heavy-duty agents that can carry real intellectual work. We believe the next frontier is not just broader knowledge or more polished conversation, but systems that can sustain long-chain reasoning, engage with uncertainty, interact with the world, and converge on better answers for critical tasks. Built on this philosophy, our MiroThinker family is more accurate and reliable, capable of handling long, demanding tasks with stronger verification and better grounding in reality. Our flagship agent MiroThinker-H1 achieves state-of-the-art performance on deep research as well as specialized scientific and financial benchmarks.
Performance Evaluation
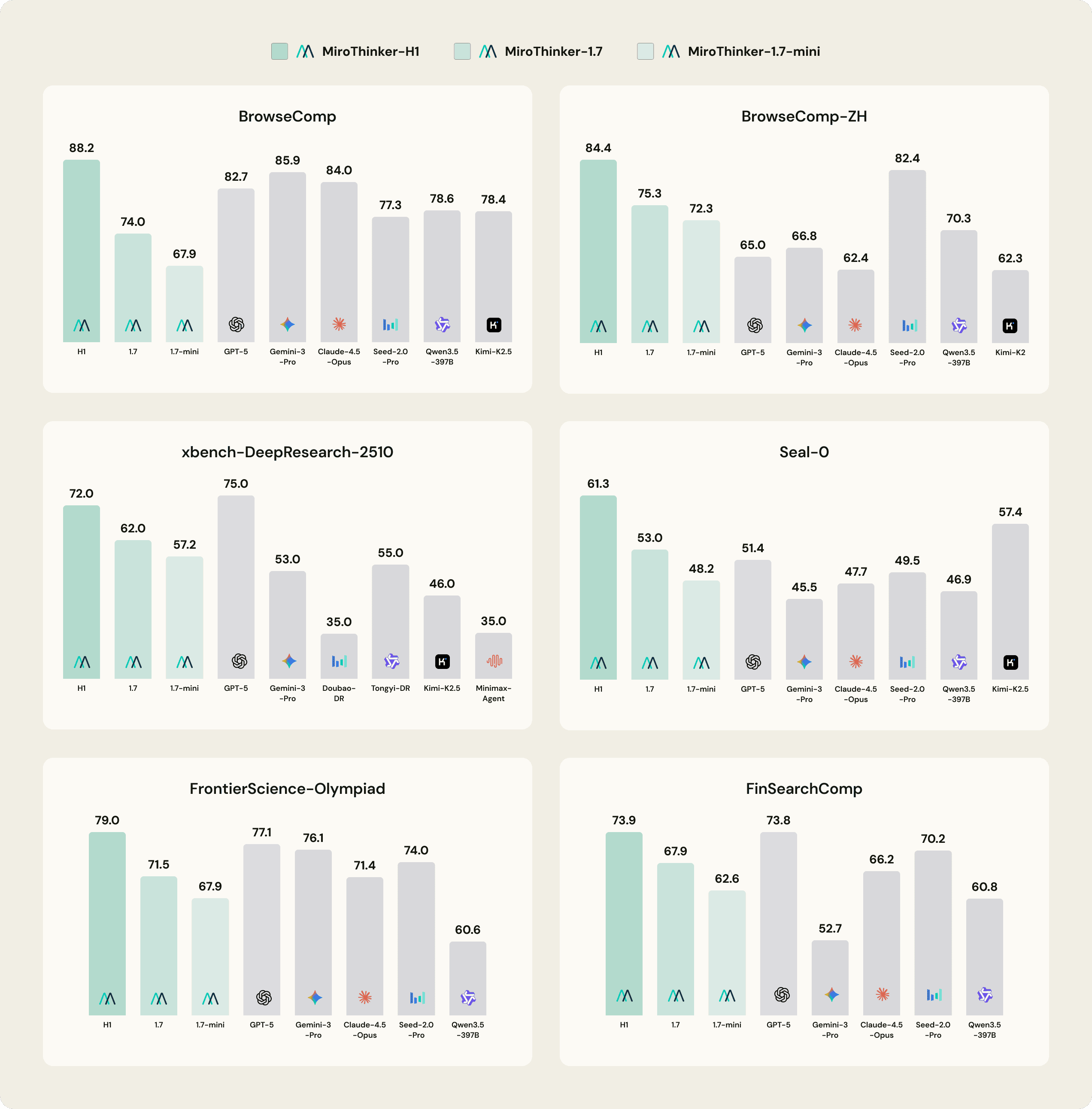
* Please refer to Hugging Face and GitHub for more details. We report the latest publicly available benchmark results for competing models.
1. Setting the New Frontier in Agentic Intelligence
As AI transitions from simply answering questions to executing complex tasks, the ability to navigate, parse, and synthesize information from the open web has become the critical differentiator. Our MiroThinker family excels in these agentic workflows, particularly in the BrowseComp and BrowseComp-ZH benchmarks, which measure a model’s ability to perform high-level research in both English and Chinese. MiroThinker-H1 achieves SOTA results on BrowseComp and BrowseComp-ZH, outperforming every major model in the industry. It also maintains a substantial lead over the most capable open-source models. Our open-source models, MiroThinker-1.7 and MiroThinker-1.7-mini, remain highly competitive in this space while maintaining superior efficiency.
2. Specialized Excellence in Scientific and Financial Domains
The reasoning capabilities of the MiroThinker family extend far beyond general browsing into highly technical domains. In scientific research and advanced mathematics, MiroThinker-H1 sets new benchmarks on FrontierScience-Research and FrontierScience-Olympiad, surpassing leading closed-source frontier models. This level of performance is mirrored in the financial sector, where MiroThinker-H1 leads the field on FinSearchComp (T2/T3), demonstrating its utility for high-precision economic analysis.
Core Insight: Scaling Interactions That Matter
We hold a foundational view: interacting with real-world feedback is not an auxiliary to problem-solving, but the core mechanism. Our team has been committed to this belief from the beginning, training models to actively seek evidence, test hypotheses, and revise until convergence, making external grounding native to reasoning itself. Unsurprisingly, the most intuitive form of interactive scaling, more turns, more tool calls, and more retries can deliver quick wins on benchmarks.
However, scaling interaction turns is not the same as scaling effective interactions. When intermediate steps fail to meaningfully advance the solution, additional interaction only amplifies noise, compounds errors, and produces motion without progress. On truly long-horizon problems, this noise is not merely waste but debt: it inevitably erodes the model's potential for deeper reasoning.
Recognizing this, we refused to treat interaction volume as a proxy for capability, and instead turned to improving interaction quality along two dimensions. On one hand, we continue to deepen the reasoning depth and precision of our agents across diverse scenarios, as this is the foundational core capability for tackling longer-horizon tasks. On the other hand, we aim to make each individual step more accurate and reliable, strengthening the quality of intermediate decisions so that interaction scaling reflects genuine progress rather than accumulated noise.
In practice, this requires the agent to slow down: to pause, verify, weigh alternatives, and deliver answers deliberately, ensuring a higher likelihood of doing the right thing rather than just doing things. Far from being a limitation, this is precisely the character of a heavy-duty solver: one built not for speed, but for the genuinely hard, high-value problems that demand it.
Key Technology
To realize this vision, we introduce two major technical upgrades. The first improves the quality of each atomic agent step, so that interaction becomes more deliberate and reliable at the local level. The second improves the system’s ability to search across alternatives and verify before commitment, making interaction becomes more trustworthy at the global level. Together, they move interactive scaling beyond simply increasing trajectory length, towards scaling interaction that produces more grounded and reality-answerable progress.
1. Upgrading Agent-Native Training

The first upgrade begins with a simple observation: if the primitive actions of an agent are noisy, shallow, or weakly grounded, scaling interaction will only scale inefficiency. More turns cannot compensate for weak step quality. To make interactive scaling truly effective, we should first improve the model’s agent-native competence — its ability to form sound local judgments, take reliable intermediate actions, and stay on track throughout long-horizon problem-solving.
To this end, MiroThinker-1.7 introduces mid-training as a new and central stage in the training pipeline. During this stage, we synthesize large-scale data focused on planning, reasoning, and summarization, while significantly expanding the diversity of task domains. This stage provides the model with a much stronger native foundation for agentic behaviors: it becomes more capable of decomposing goals, selecting appropriate tool calls, interpreting tool responses, and synthesizing final answers. As a result, each individual step in the interaction process becomes more reliable and grounded, establishing a stronger basis for effective interactive scaling.
Building on this new foundation, the later stages of training (Supervised Fine-tuning, Preference Optimization, and Reinforcement Learning) further shape these capabilities into more structured and robust long-chain behavior. Collectively, these stages enable the model to sustain accurate reasoning and grounded actions across extended interaction trajectories, maintaining coherent progress toward task objectives and enabling more reliable long-horizon problem-solving.
2. Verification-Centric Heavy-Duty Reasoning Mode
Improving the quality of each reasoning step is a goal common to almost all reasoning systems. However, the real question is how to achieve this. Relying solely on the model's own reasoning ability to guarantee step-level quality is a fragile assumption.
To address this, MiroThinker-H1 introduces a verification-centric heavy-duty reasoning mode. The core belief behind this architecture is that the reliability of reasoning ultimately depends on the system's ability to examine its own reasoning process. The verifier serves as the key component throughout, operating at two levels.
Local verification. Break probability bias to fully explore the right path, not just the likely one.
Global verification. Audit the full chain of evidence so the best-supported answer wins, not the most confident one.
Under this mode, beyond significant gains in accuracy, we observe a promising phenomenon: the number of interactive steps decreases substantially. This indicates that the verifier is essentially filtering out steps that produce no information gain, concentrating compute on interactions that genuinely advance the solution. Fewer steps do not contradict "heavy-duty." On the contrary, they lay the groundwork for further scaling of effective interaction.
Sample Showcase
Financial Case: Gold Price Prediction
0.08% Error, 15 Days in Advance
Prediction time: February 10, 2026
Question: What will be the GOLD price (XAU/USD) on February 25, 2026?
MiroThinker prediction: Applied a 3-factor model (real interest rates / USD credit & policy credibility / geopolitical risk). Identified gold at ~$5,040 baseline, all three factors pointing bullish. Predicted $5,185/oz for Feb 25.
Actual Result: Fortune quoted $5,181, 150 Currency quoted $5,185.89, and CME GCG26 settled at $5,206.40
Judgement: ✅ Spot-on. Error: $4 (0.08%),15 days in advance
Verification source: Fortune · Money.com · RoboForex
dr.miromind.ai/financial-case
Sports Case: Super Bowl LX Winner Prediction
Correct Champion, 1 Month in Advance
Prediction time: January 6, 2026
Question: Who's going to win the 2026 Super Bowl?
MiroThinker prediction: Identified the Seattle Seahawks as the most likely Super Bowl LX champion.
Based on betting odds of +350 to +400, implying roughly 20–25% win probability
Also noted the Seahawks’ 14–3 regular season record and No. 1 NFC seed
Actual Result: On February 8, 2026, the Seattle Seahawks defeated the New England Patriots 29–13 to win Super Bowl LX
Judgement: ✅ Correct champion prediction, made 1 month in advance
Verification source: NFL / Super Bowl LX official result
dr.miromind.ai/sports-case
Entertainment Case: Grammy 2026 Dominance Prediction
Kendrick Lamar Correctly Called, 3 Weeks in Advance
Prediction time: January 8, 2026
Question: Which artist is most likely to dominate the 2026 Grammy Awards?
MiroThinker prediction: Identified Kendrick Lamar as the artist most likely to dominate the 2026 Grammy Awards
Noted that he led the field with 9 nominations
Highlighted nominations across all three major categories: Album, Record, and Song of the Year
Referenced the historical pattern that the most-nominated artist often emerges as one of the night’s biggest winners
Actual Result: At the 68th Grammy Awards on February 1, 2026, Kendrick Lamar won 5 awards, including Record of the Year for “Luther,” and emerged as the biggest winner of the night
Judgement: ✅ Correctly predicted the dominant artist, 3 weeks in advance
Verification source: Recording Academy / Grammy Awards official results
dr.miromind.ai/entertainment-case
About Miromind
Mirror and Connect Human Intelligence and AI.
Miromind is a Singapore-based AI applications company building intelligent prediction agents, powered by the global open-source ecosystem.
Our Vision:
Founded by renowned entrepreneur Tianqiao Chen, Miromind.ai is dedicated to building "General Purpose Solver 300 Steps to 99% Certainty" - moving from probabilistic generation to verifiable accuracy. We believe this paradigm will unlock a new generation of discovery AI systems that are more capable, reliable, and trustworthy for complex real-world problem solving.
We invite you to explore our work and try the demos: Product, Hugging Face, and Github. The next generation of intelligence is not just about conversation—it is about deliberate, long-chain reasoning with 99% cumulative accuracy. If you're excited about building this future, we'd love to hear from you: 📧 talent@miromind.ai.


